Ungefär 0 koll på siffrorna, dessutom
19 mars 2005 | 18 kommentarer
Varför har datorer 0 koll(ar) på grammatiken? undrar Tommy på användbart.se.
Ännu konstigare är kanske att datorerna också har så svårt att räkna. Tror du inte på det? Jo, men titta här nedan. De flesta människor kan lätt räkna till 33. Men vår älskade Google förefaller faktiskt ha problem med det, så allvarliga att den måste gissa – om vi ska tro vad den faktiskt säger:
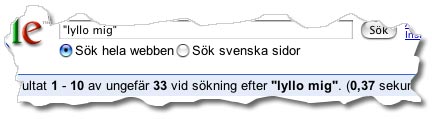
Vad vi egentligen ser är förstås just det som Tommy tar upp: nonchalansen mot språket.
Här blir det extra komiskt när Google däremot levererar information om något som är fullständigt ointressant för mig med största exakthet: sökningen tog 0,37 sekunder.
Just detta är väldigt vanligt i många sorters gränssnitt: alldeles för detaljerad information om saker som antingen inte är väsentliga för användarna, eller som de redan vet …
Kategori: Webb och IT
Kommentarer
18 kommentarer to “Ungefär 0 koll på siffrorna, dessutom”
Kommentera
mars 19th, 2005 @ 15:44
Och bläddrar du vidare bland resultaten så kommer du inte så långt:
”Vi har uteslutit vissa svar som var snarlika 17 som redan visats för att kunna ge dig de mest relevanta resultaten.”
Först 33, och sen 17? Varför tror du dom gör på detta viset? Jag kan lova dig att dom vet exakt vad dom gör, och varför.
mars 19th, 2005 @ 15:48
(och tidsangivelsen är naturligvis en del av varumärkesbyggandet)
mars 19th, 2005 @ 16:12
Dra mig baklänges på en tallpinnevagn, men jag är helt säker på att uppgiften om hundradelssekunderna är fullständigt oväsentlig för användarnas goda uppfattning om Google.
mars 19th, 2005 @ 16:18
”Ungefär” är alldeles vettigt när man får ett stort antal träffar och Google avrundar till ”ungefär 170 000”.
Men villken funktion menar du att det skulle ha här? Som en sorts disclaimer, vi hittade 33 men det kan finnas fler?
mars 19th, 2005 @ 16:43
Rent tekniskt tror jag förklaringen finns någonstans i att det finns ett sätt att räkna (t.ex. utan att plocka bort duplikaten, och kanske utan hänsyn till viss avancerad söksyntaxen) som inte är så resurskrävande, och att det är detta som används för att ange den ungefärliga totalsiffran. Om användaren sedan verkligen klickar vidare för att se sökträffarna använder systemet den mer exakta men också mer resurskrävande metoden för att ta fram de träffar som verkligen skall visas.
Jag tycker inte det är en tiondel så irriterande hos Google som hos Word, som på första sidan i en utskrift kan säga ”sid 1 av 20” för att sedan på sista säga ”sid 22 av 22”.
mars 19th, 2005 @ 16:51
”jag är helt säker på att uppgiften om hundradelssekunderna är fullständigt oväsentlig för användarnas goda uppfattning om Google”
Och jag kan lova dig att om det vore så skulle dom ha tagit bort den för länge sen…
mars 19th, 2005 @ 17:02
Detta kan ju testas på olika sätt.
Vi kunde vi visa en Google-sida, där vi suddat bort söktidsuppgiften för ett antal användare, och fråga om de upplever någon skillnad. Jag lovar dig att ingen skulle se det.
Eller vi kunde visa dem sidor där vi ersatt den typiska siffran 0,37 sekunder med 0,78 sekunder eller till och med 3,7 sekunder. Jag lovar dig att så gott som inga skulle märka det heller.
Jag förutsäger att ingen heller skulle tycka att det spelade någon som helst roll, om man sedan påpekade det för dem.
Om något som ingen ser, ingen kommer ihåg och ingen tycker är väsentligt ändå påverkar ”varumärket” är det som jag länge misstänkt – att det handlar om helt metafysiska, religiösa föreställningar…
mars 19th, 2005 @ 17:30
Tommy är inne på rätt spår; sökmotorn vet normalt *exakt* hur många träffar den har, men träffmängden är inte samma sak som resultatmängden, och den senare plockas fram efterhand.
Ungefär såhär funkar det:
I ”lyllo dig”-exemplet söker motorn fram ”lyllo” och ”dig”, och väljer ut dom URL:er där ”lyllo” står direkt före ”dig”. Detta ger 37 träffar.
När den första resultatsidan ska visas letar motorn rätt på dom 10 högst rankade träffarna bland dessa 37. Sedan tittar den efter dubletter och grupperingar, och fyller på med lägre rankade träffar om så krävs.
I samband med detta försöker motorn också gissa hur många träffar som kommer att behöva plockas bort totalt (i detta fall underskattar den rejält, och gissar på 4 istället för 20). Den exakta siffran minus gissningen blir en ”ungefärlig” siffra (som avrundas på lämpligt sätt om den är tillräckligt stor).
När du sen klickar dig fram till nästa sida plockar motorn fram dom 10 nästa träffarna enligt rankingen, och eliminerar dubletter och grupperar resultatet som förut. Detta upprepas för varje ny sida, tills träffarna tagit slut, eller totalt 1000 resultat har visats.
Tar träffarna slut så visas normalt ”vi har uteslutit”-texten, och du kan då göra om sökningen med en (delvis) bortkopplad dublettkoll. När du gör detta försvinner också ordet ”ungefär” från den sista resultatsidan; när google vet att du tittar på den sista träffen behöver dom inte längre gissa.
(skulle det funka bättre med ”preliminärt” istället för ”ungefär”? tveksamt…)
mars 19th, 2005 @ 17:37
”Vi kunde visa en Google-sida, där vi suddat bort söktidsuppgiften för ett antal användare, och fråga om de upplever någon skillnad. Jag lovar dig att ingen skulle se det”
Google gör naturligtvis tester av detta slag kontinuerligt. Finns något på sidan är det för att testerna visar att tillräckligt många använder upplever detta något som positivt.
(google testar allt hela tiden. saker dom kan mäta effekten av över nätet, som till exempel formuleringen på olika texter, placeringen av olika sidelement, etc, testas kontinuerligt. I bland kan en ide testas i några minuter på ett urval servrar; det räcker för att man ska få tiotusentals observationer…)
mars 19th, 2005 @ 17:39
”tillräckligt många använder” => ”tillräckligt många användare”
(lite större kommentarruta skulle inte skada. eller jag kanske skulle skriva lite kortare kommentarer?)
mars 19th, 2005 @ 20:38
En intressant detalj är att det ungefärliga totalantalet kan variera ganska kraftigt. Jag gjorde en googling och tryckte sedan reload några gånger. Första gången fick jag ungefär 425 träffar, sedan 422, 381, 416 och 386.
mars 19th, 2005 @ 20:41
Hm, gick visst inte att lägga in en länk…
Googlingen var ”1 of 0” på sidor från Sverige (länk: http://www.google.se/search?hl=sv&q=%221+of+0%22&btnG=S%C3%B6k&meta=cr%3DcountrySE )
mars 19th, 2005 @ 20:42
Inte nog med att datorer är för lata för att räkna i största allmänhet – de klarar inte ens den mest grudläggande matematiken: att skilja mellan något och inget: http://www.anvandbart.se/node/126
mars 20th, 2005 @ 01:23
Det finns säkert tekniska skäl till att man inte har en exakt siffra: men det som skaver i läsarens huvud är kontrasten mellan ”ungefär” och ett följande exakt och litet tal, som 11 eller 17 eller 23. Det vore i så fall bättre att avrunda även detta tal: det bästa vore sannolikt att ange det som ”drygt 10”, ”knappt 20” eller ”drygt 20”.
Visst testar säkert Google en hel del, men tro mig, jag har gjort många användarstudier, och det är inte alls så lätt att se eller mäta användarnas åsikter om varenda liten detalj.
Sekunduppgiften har väldigt låg imponans-kraft, framför allt eftersom vi har så svårt att relatera den till något annt. Vi vet inte hur många sidorman sökte igenom, eller ens hur lång tid det *borde* ta att söka igenom så många sidor, eller hur många tiondelar det tar för andra sökmaskiner att göra sökningen.
Siffran imponerar kanske på en liten skara tekniker. Det som gör det fånigt är kontexten, att den står alldeles intill ”ungefäret”. Vill man absolut ha kvar den skulle man mycket väl kunna flytta den til en annan position.
mars 20th, 2005 @ 07:05
Eller så är det placeringen just intill ”ungefär” som är finessen: ”Jag räknar hemskt slarvigt – MEN SE SÅ SNABBT JAG GJORDE DET”. Det vore ju litet magstarkt att kritisera någon som letat igenom hela internet på en tredjedels sekund för att han inte riktigt hinner ha exakt ordning på alla siffror…
mars 23rd, 2005 @ 21:11
Jag har sett ett resonemang (hittar inte källan) om att uppgiften om hur lång tid det tar att göra sökningen presenteras för att skylla ifrån sig om det går långsamt. I rent marknadsföringssyfte, inget som tekniksnubbarna driver.
Typ: ”Om det inte gick snabbt beror det på att du har en långsam lina, vi på Google gjorde vårt jobb på 0,37 sekunder.”
Att man kan få olika träffar och olika antal träffar om man laddar om sidan beror på att Google har massor av servrar i olika datacenter. När databasen (indexet) uppdateras går inte alla maskiner i takt och man kan få en mix av fräscht och skåpmat.
Läs mer:
http://google.com/search?q=google+dance+data+center
mars 24th, 2005 @ 17:05
Googlesökning på http://www.google.se/search?hl=sv&q=shiftl%C3%A5set&btnG=S%C3%B6k&meta=cr%3DcountrySE ger ”Resultat 1 – 1 av ungefär 2”.
maj 4th, 2005 @ 15:58
Ibland är det stor skillnad mellan ungefär och exakt…
http://www.google.com/search?q=%22Buzz+Bruggeman%22&hl=en&lr=&start=990&sa=N&filter=0